


3 reasons why controlling buildings is so hard, and how AI can help - Part 1

With the advent of artificial intelligence (AI) and machine learning, our ability to process vast amounts of data, predict outcomes, and optimize solutions has grown exponentially. This evolution has revolutionized industries, from healthcare to finance, and yet, buildings have often remained on the periphery of this transformation.
The main reason does not lie in the lack of applicability of AI in the building industry, but rather in the diverse and complex nature of building environments. Unlike some other sectors that deal with more controlled and standardized data, buildings encompass a wide array of variables, from structural design to occupant behavior, making them inherently challenging to create universally applicable AI solutions.
Additionally, the construction and real estate industries have traditionally been risk-averse and slow to adopt new technologies, further impeding the rapid adoption of AI in building management (luckily, things are changing).
In this newsletter, we delve into the metaphorical journey from "bricks to bytes", exploring how technology and innovation are reshaping the way we design and control buildings, to which this article is dedicated.
Model, Predict, Optimize
Every control problem, whether it involves a skyscraper, residential complex, or shopping mall, can be distilled into a trifecta of challenges: modelling (and simulation), prediction, and optimization. These three concepts are the foundational elements of what's known as sequential decision making, which explains how time-dependent decisions are made. The standard decision-making approach (taken from Warren Powell)1 is depicted in a framework that shows the interplay of the environment, the controller (our agent) and other exogenous information.
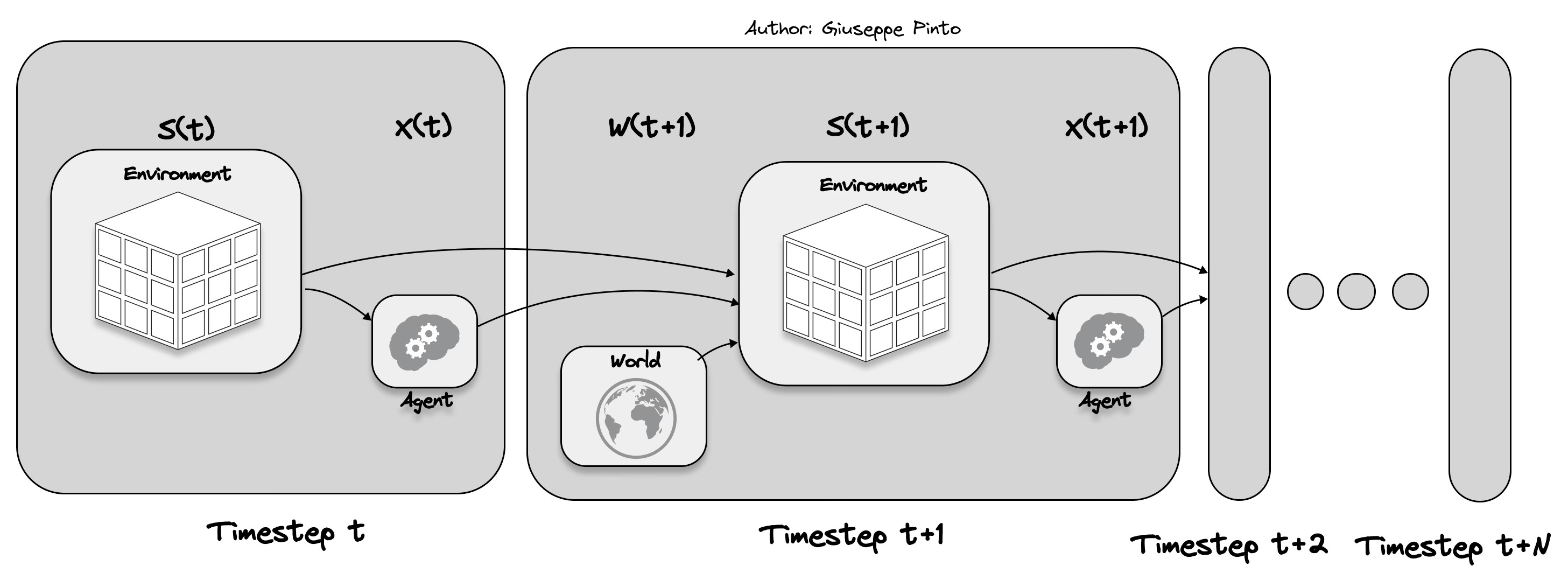
To better understand why controlling building is so hard, let’s delve into each component.
State
State information represent the various possible configurations or conditions that a system can exist in at a given moment. Although multiple definitions exist, for the sake of simplicity we will use a terminology that divides the states into environment variables (specific to the system we are trying to control) and exogenous variables (whatever is outside our control but influences our states and decisions). The state encompasses measured environment variables, unmeasured (or unmeasurable) environment variables, and exogenous information.
Measured environment variables include data collected from sensors within the building, such as temperature, humidity and energy consumption.
Unmeasured/unmeasurable environment variables, on the other hand, are aspects that are not directly observed, like occupant comfort (costly to measure) or the remaining life of a component (unmeasurable).
Exogenous information pertains to external factors that influence the building but aren't intrinsic to it, such as weather or utility prices, which may or may not be fully known.
The picture below describes a typical building system and the state description according to the previous definition.
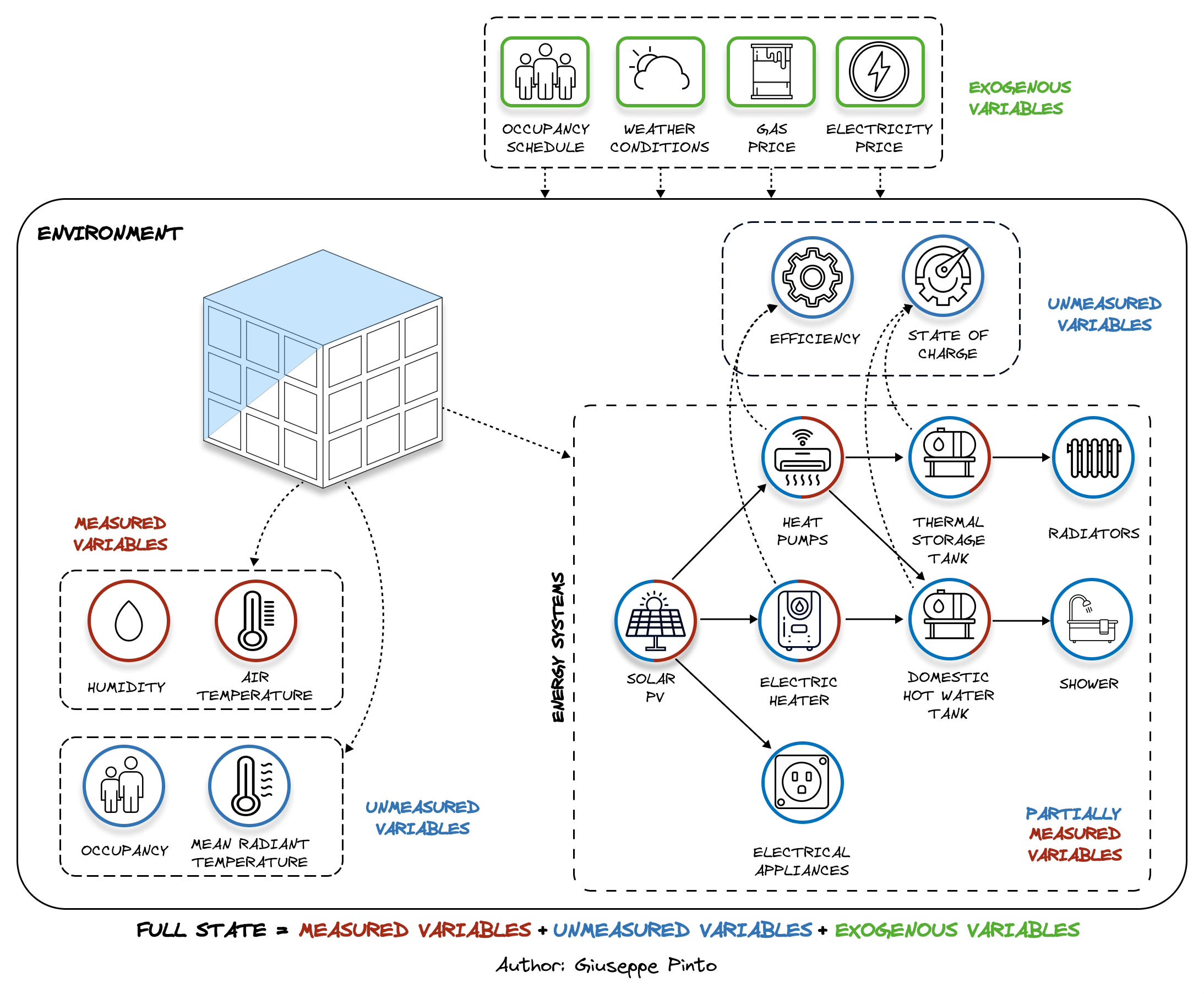
Looking at the image, it is clear that unmeasured and exogenous variables outnumber the measured one, increasing the complexity of the problem.
Decision variables
Decision variables2 represent the actions or adjustments that can be made within the controlled system. These variables can include set points for heating, ventilation, and air conditioning (HVAC), adjusting lighting levels, or managing the use of renewable energy sources and storage. These decisions are at the core of actively managing and optimizing the system's performance.
Exogenous information
As mentioned earlier, exogenous information comprises all the events and factors that occur independently of our control actions but wield a significant impact on our system's evolution. Exogenous information at time t+1 is what we learn after making a decision. This may include future weather conditions, occupancy schedules, or the evolving electricity prices influenced by market dynamics. These pieces of information are particularly relevant in the context of thermodynamic systems (i.e. mechanical equipment using a refrigeration cycle or radiative heat transfer through non-opaque surfaces), which are notably sensitive to changes in weather conditions.
Transition Model
The transition function describes how the state evolves over time in response to the chosen decision variables and exogenous information. This concept is also known as system model, system dynamics or digital twin, and aims to capture the cause-and-effect relationship between actions taken and their impact on the state. For example, for a building its thermodynamic model is fundamental to ensure comfort, describing the evolution of indoor condition when heating/cooling is injected.
Objective Function
The objective function defines the goal or performance metric that the control system aims to optimize. In particular the policy (π) it aims at minimising the cost over a certain time horizon (T), that is evaluated using the states and the actions we take. Common objectives for building control include occupant comfort, energy efficiency, cost savings, environmental sustainability, or some combination of these objectives.
The following figure displays the interaction of the different pieces, highlighting the complexity of the control problem and the information exchange that happen at every time step.
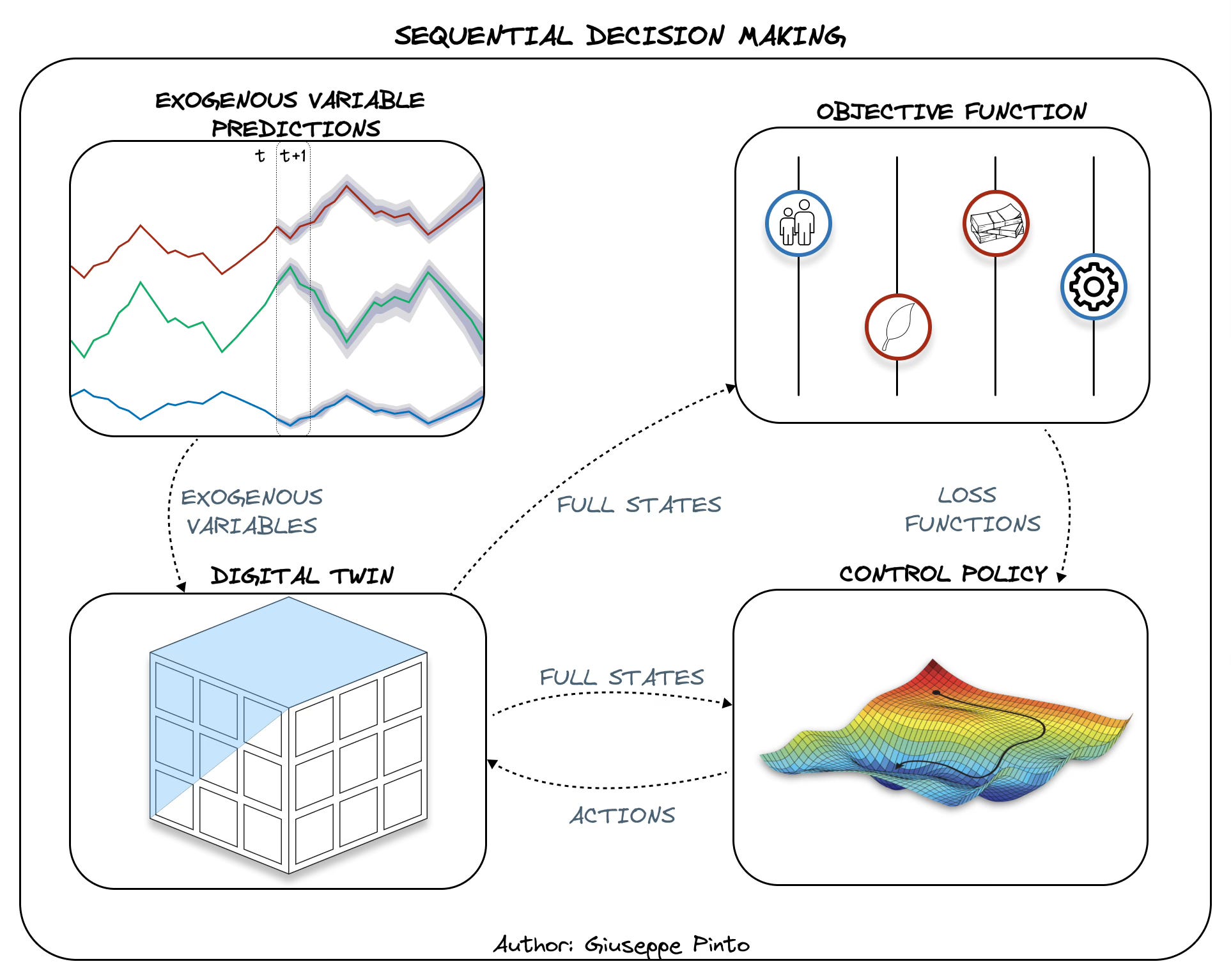
So, why is it So Hard to Control Buildings?
The answer lies in 3 key aspects:
How can I optimize something that I can't (directly) measure?
How can I predict the evolution of my building?
How do I select the best actions over time?
How can I optimize something that can't be (directly) measured?
Despite the kind of control policy that we are going to use for our decision variables, control aims to maximize/minimize an objective function that can only describe what can be measured, or inferred, and that’s one of the reasons why controlling building is so hard.
Let's take the average objective function for a building, displayed in the figure below. This function is made up of two conflicting terms, minimizing discomfort while minimizing costs.

In the vast majority of cases we are only able to measure a few of these variables, making the evaluation of the objective function strongly influenced by how good our assumptions and inferred measurements are.
Even though we attempt to quantify and bound comfort (i.e. ASHRAE Standard 55)3 , it is an entirely subjective measurement. So, to make the problem tractable, we approximate comfort with one (maybe two) variables that can readily be measured: temperature and humidity. Reality is that most buildings do not have enough air temperature and humidity sensors, let alone methods to figure out how many people are inside a room and its indoor air quality information to better quantify comfort.
The same considerations can be extended to evaluate the cost associated with running the energy systems in the buildings, influenced by the amount of energy spent, in turn influenced by the occupancy in the building and other external variables, often not measured.
Combine this with the fact that each building is designed and used in a different way, and we unveiled one of the main reasons why controlling buildings is so hard. Is it a sensor problem then? (Yes, and no.)
Sensors are fundamental to provide information at present time and also gathering current/historical data, but they can’t provide values into the future (we will come back to this later), and in order to perform better sequential decision making that’s exactly what we need.
How can I predict the building’s evolution?
This leads us to the second pain point on why it is so hard to control buildings. We need information about the evolution of the full state, which is made up of environment variables and exogenous variables.
Environment variables describe all the variables characterizing the building and the energy systems, for the building they can be building materials’ properties, air temperature, humidity, mean radiant temperature, while for the systems we could have mass flow rate, air/water temperature, pressure, system efficiency. However, as previously said, the amount of unmeasured data in buildings is way bigger than the measured one.
This can be explained looking at two crucial aspects that makes the building industry so unique:
Buildings are like snowflakes, in that no two are exactly alike, and they exhibit a remarkable diversity of shapes, materials, and energy systems, making each one a unique entity in the urban landscape. While this may sound romantic, it's worth noting that in many industries, standardization has been embraced for very good reasons. The easiest comparison can be made looking at cars; in the automotive industry, car manufacturers produce vehicles according to established standards and specifications. Now, imagine if every car were as unique as a snowflake, it would make diagnosing and repairing issues, understanding fuel efficiency, or assessing performance incredibly complex.
The availability of sensors in buildings is often limited. First, costs can be a significant barrier, as deploying and maintaining sensors can be expensive. Second, the diversity of building types and designs necessitates customized sensor solutions, creating a loop in which the absence of modelling and the lack of advanced control stopped the incentives to install sensors, as customers not perceive a clear benefit in installing them. When considering modern cars, it's interesting to note that they can be equipped with a substantial number of sensors, ranging from 50 to 100, all with a singular focus: controlling three essential functions—steering, braking, and acceleration. In the same context, buildings very easily have (or better, should have) hundreds or thousands of sensors and hundreds or thousands of controllable variables.4
The lack of sensors leads to a huge gap between what we could do and what we do in terms of modelling. Indeed, they play a crucial role in validating models. Given the complexity of the built environment, multiple models (such as thermal, hydraulic, electrical, and structural) need to be integrated into a larger model, commonly known as digital twin. In the context of buildings, a digital twin is a virtual replica of a physical building that captures the entire building's characteristics, including its architectural design, systems and operational data. The goal of creating a digital twin is to provide a comprehensive and dynamic view of a building's behavior, facilitating advanced control strategies and maintenance. Therefore, one of the problems is finding a methodology to automate the creation of digital twins, building on the available sensors and reducing costs and time associated to its creation.
Unfortunately, this is only half of the problem. Even if we could perfectly capture the building’s characteristics for simulation purposes (insulation, construction deficiencies, equipment characteristics), there are many influential variables that require forecasts. These are referred to as exogenous variables and include weather, electricity price and occupancy forecasts. Depending on the applications, weather evolution influences energy production, and in turn electricity prices. Lastly, occupancy prediction is by far the hardest thing to predict in a granular way, as patterns can widely vary throughout the day, week and year. Furthermore, human behavior is not always predictable, and events like holidays or sudden changes in work schedules can lead to unexpected variations in occupancy patterns, especially transitioning from building level to specific rooms.
When examining the objective function, it becomes evident that the prediction of these variables (number of people, external temperature, and solar radiation) has a significant influence on the system's behavior. Therefore, it's crucial to account for the uncertainties associated with these predictions when seeking the control policy.
How do I select the best actions over time?
This lead us to our third point, selecting the best action once we gathered all the information. In decision-making and control, a policy is a fundamental strategy that guides how an agent or system should respond to varying states. It defines the actions to be taken based on the current observed state, serving as the logic that connects the system's perception of its environment to its actions, ultimately helping it achieve its goals.
There are two main strategies for designing policies:
Policy search: use a set of parameters θ (that needs to be tuned) to create a state-action map that maximize or minimize an objective function.
Policies based on lookahead approximations: build the policy so that we make the best decision now, considering an estimate (which is typically approximate) of how the decision will affect future outcomes.
These two family of policies can further be categorized as follow:
Policy search
Policy function approximation: (rule-based control, data-driven control, reinforcement learning) follows simple rules and procedures that map a state to an action, like look-up tables, parametric functions or non-parametric functions (neural networks). In the building context, the most common scenario is using a look-up table that aims at maximizing comfort. In order to do so, the first approximation is to use the air temperature to simulate comfort; then, based on the air temperature value, we create a simple function that turns on the heating when the temperature is lower than 19°C and switch it off when it reaches 21°C. This is the most widely used class of policies, applied in almost every building through the Proportional–integral–derivative controller (PID)5 . Other examples are related to rule-based control for storage energy management, such as charging the storage when energy prices are low and discharging it when prices are high.
Cost function Approximation: (rule-based control, data-driven control) minimize or maximize some analytical function, artificially modifying the cost function introducing a modified set of constraints. For storage energy management optimization we could say that we are going to optimize the operation using the previous rule-based control, but we will add a constraint saying that the storage state of charge can’t be lower than 20%, to account for unpredictable events that would require additional energy.
Lookahead policies
Value function approximations (discrete stochastic programming, dynamic programming, approximate dynamic programming, reinforcement learning). It involves estimating or approximating the value function, which represents the expected cumulative rewards or costs associated with different states or state-action pairs in a system. Using the storage as an example, a reinforcement learning policy could learn through trial and error the value of being in certain states based on the fluctuating prices and expected benefits over time, optimizing its operation.
Direct lookahead policies: (model predictive control, robust optimization, stochastic programming) here we approximate uncertainties, the transition function model, the decisions and/or how we are making them. These policies look into the future and evaluate potential outcomes before selecting an action. For instance, model predictive control algorithm can leverage the model to “look into the future” and assess various scenarios based on predicted energy prices, deciding when to charge or discharge the energy storage system to minimize costs over a certain time horizon.
Each approach has its own pros and cons. Policy search is simpler, but its simplicity is often associated with either suboptimal performance or the necessity to tune a lot of parameters, rule based control and PID are clear examples. On the other hand, lookahead policies try to understand the contribution of an action over the whole control horizon, either by using approximations of transition functions (less compute intensive) or directly navigating the associated complexity (more compute intensive).
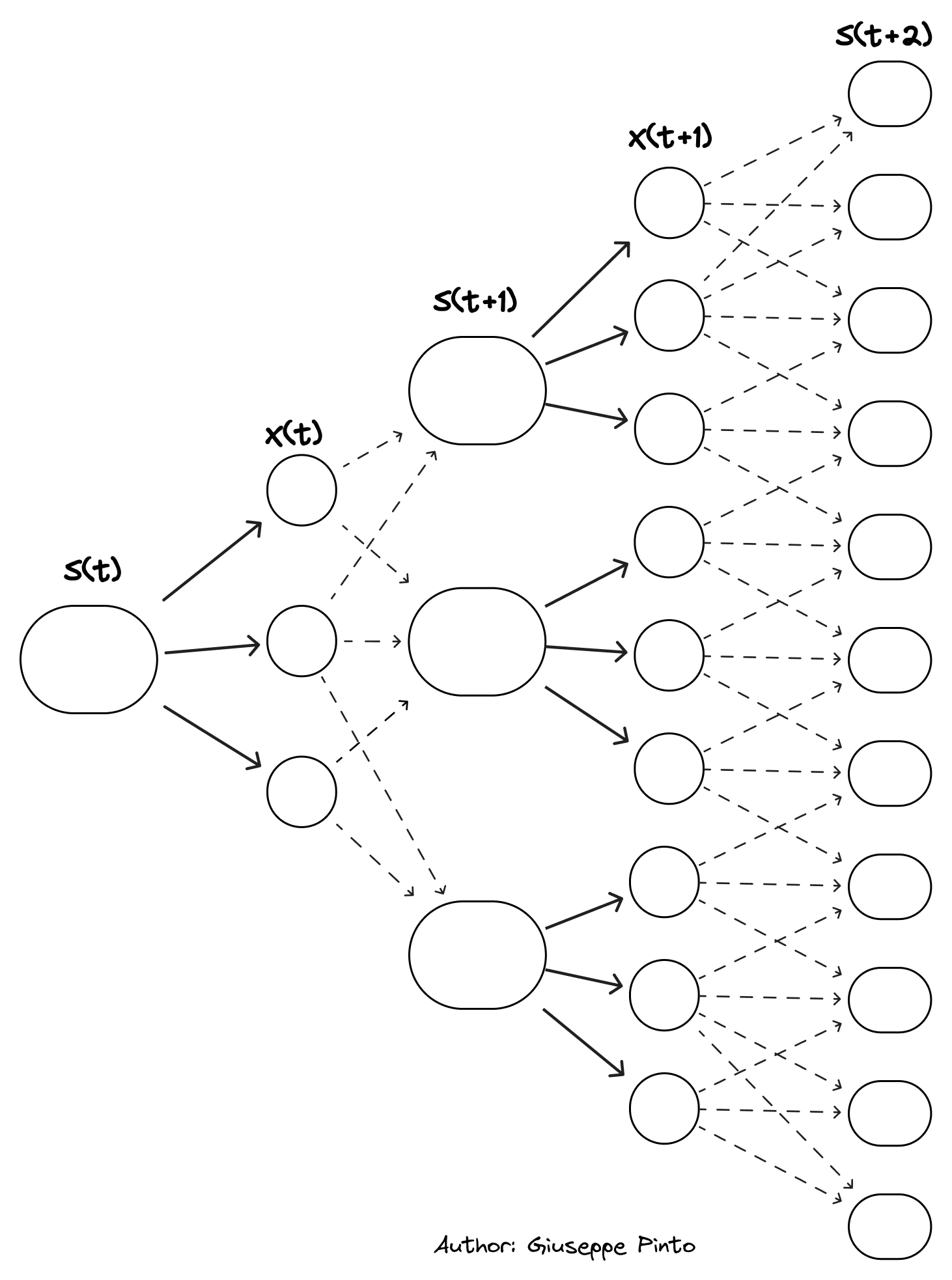
This figure shows the evolution of the system, and how it is influenced by our action, but also by uncertain future events that can affect the system (external price signal, weather events, change in occupancy). As the source of uncertainties grow, the complexity of the system explode, making finding the control policy harder. Furthermore,the dependencies between different time steps contribute to this exploding problem. A clear example of this is the use of thermal storage and batteries. These mechanisms enable us to decouple production from consumption, allowing us to save energy if we are able to exploit the dynamics of the system and the variability of the electricity price. In recent years, lookahead policies have garnered significant attention due to the escalating complexity of modern building systems, however their use in real-world scenario is limited by their computational cost and/or the associated effort to create detailed models.
Now that we've explored the hurdles of building control (and have a common dictionary), the next part of this article will dive into how AI can help solving those problems, fast forwarding us from a 100 years old PID to autonomous control (or so).
For an introduction on sequential decision making, this book is a must read, while if you want to deep dive into the topic, the extended version can be found here. Powell W.; Reinforcement Learning and Stochastic Optimization: A unified framework for sequential decisions
A policy (π) select the decision variables (X) based on the current state (S)
This article by Troy Harvey clearly explains the necessity of standardization in buildings, and how sensors, simulation and control are interconnected drawing on the comparison between cars and buildings
Despite its simplicity, PID is not able to handle multi-objective functions, and its reactive nature makes him highly suboptimal for energy-intensive systems such as heating and cooling.