


5 challenges of scaling AI predictive applications in buildings
The story of an energy community

While looking at building control, scaling prediction models is essential to meet the diverse and evolving energy needs of different structures. These models enable more accurate energy usage forecasts, crucial for optimizing efficiency and reducing costs. As buildings vary greatly in design and function, scalable models ensure that each structure's unique characteristics are accounted for, enhancing sustainability and operational effectiveness.
What does it mean to scale predictive applications?
There are mainly two ways of scaling predictive applications: scale-up and scale-out (and a mix of both).
Scale-up: refers to the process of increasing the size or capacity of a single system or operation, enhancing its ability to handle more significant loads or more complex tasks. In the context of building prediction models, scaling-up a prediction model involves shifting the prediction from a single building to a district or a city.
Scale-out: refers to increasing the number of systems or operations, essentially replicating a successful model across multiple units or locations. In the context of building prediction models, scaling-out a prediction model means maintaining the focus on the building performance, but applying it to multiple buildings.
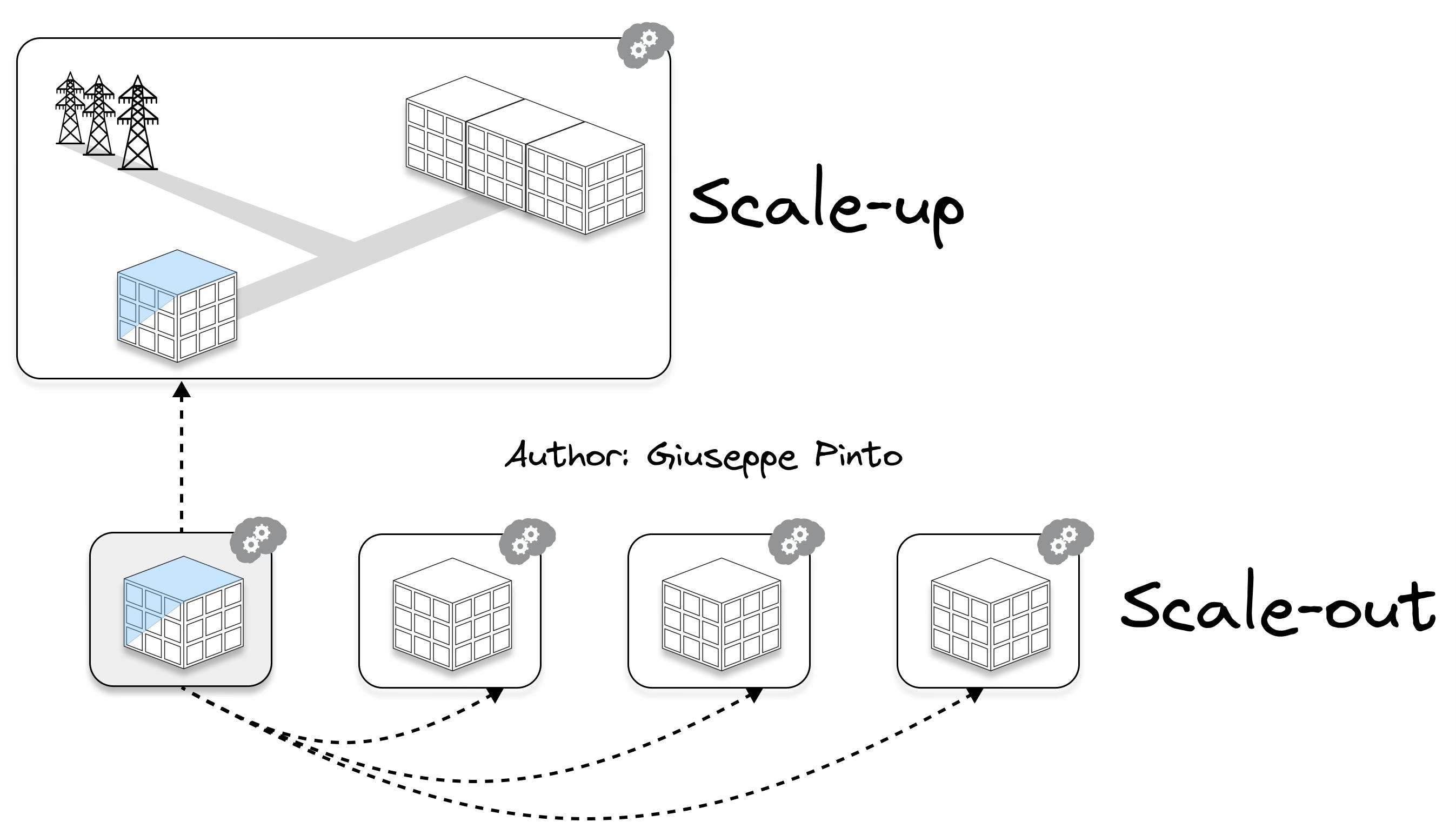
Scaling applications from single buildings to energy communities
To understand the challenges faced when trying to scale the use of prediction models, let’s consider the following example:
A small house decides to join an energy community to cut down on costs. The owner doesn't plan to change their energy use, but the community is connected to a storage system. This system charges when electricity prices are low and discharges when they're high. There's a catch, though: the electricity price of the whole community depends on the community's peak-to-average ratio over the day. So, the higher the demand, the more everyone pays.
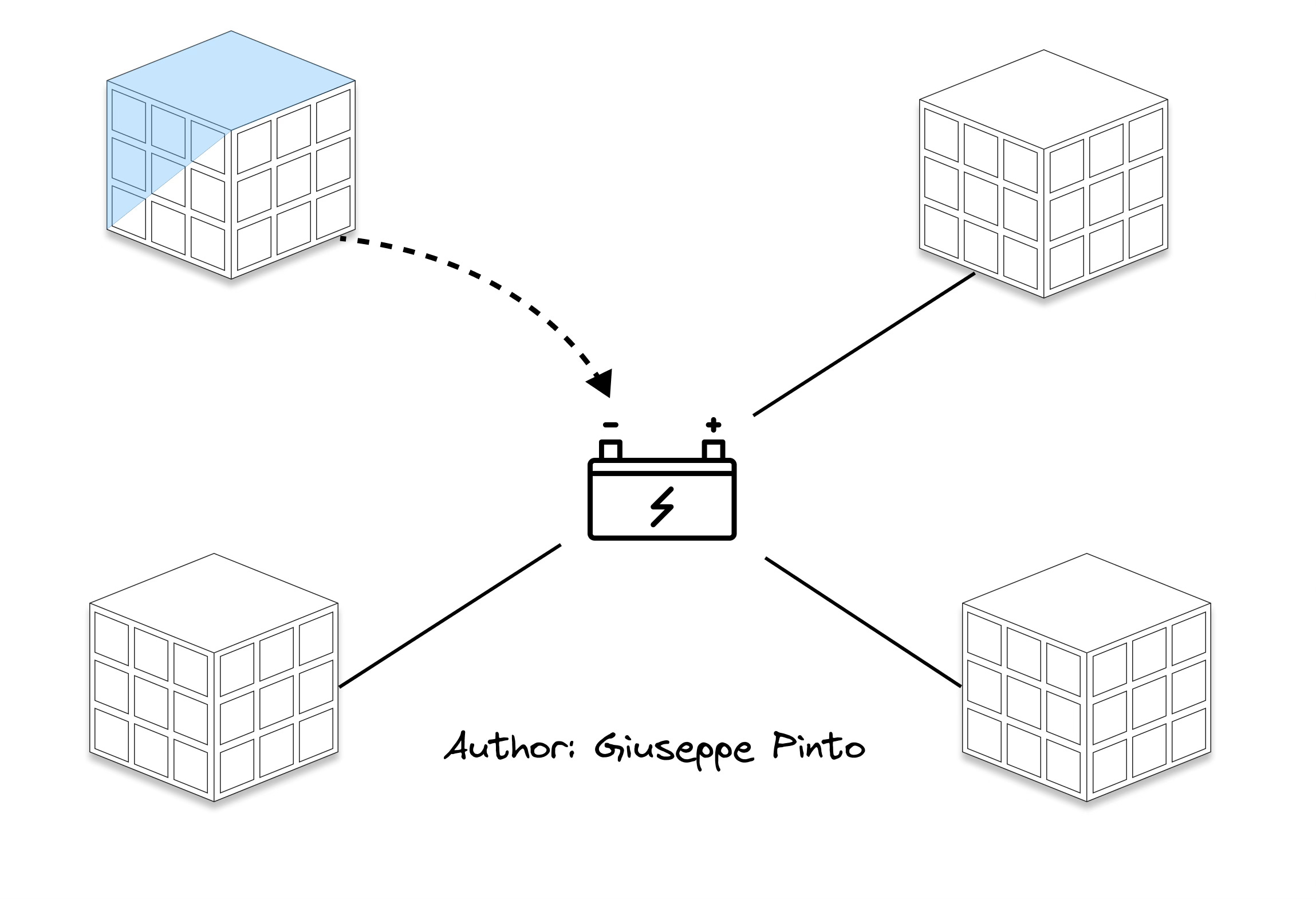
The starting point is creating a model to predict the electricity use of the house, for example using a simple neural network with a few key variables. Then, we have to repeat this process for each house to figure out the community's total energy load. This brings us to three of the five main challenges in scaling predictions for buildings:
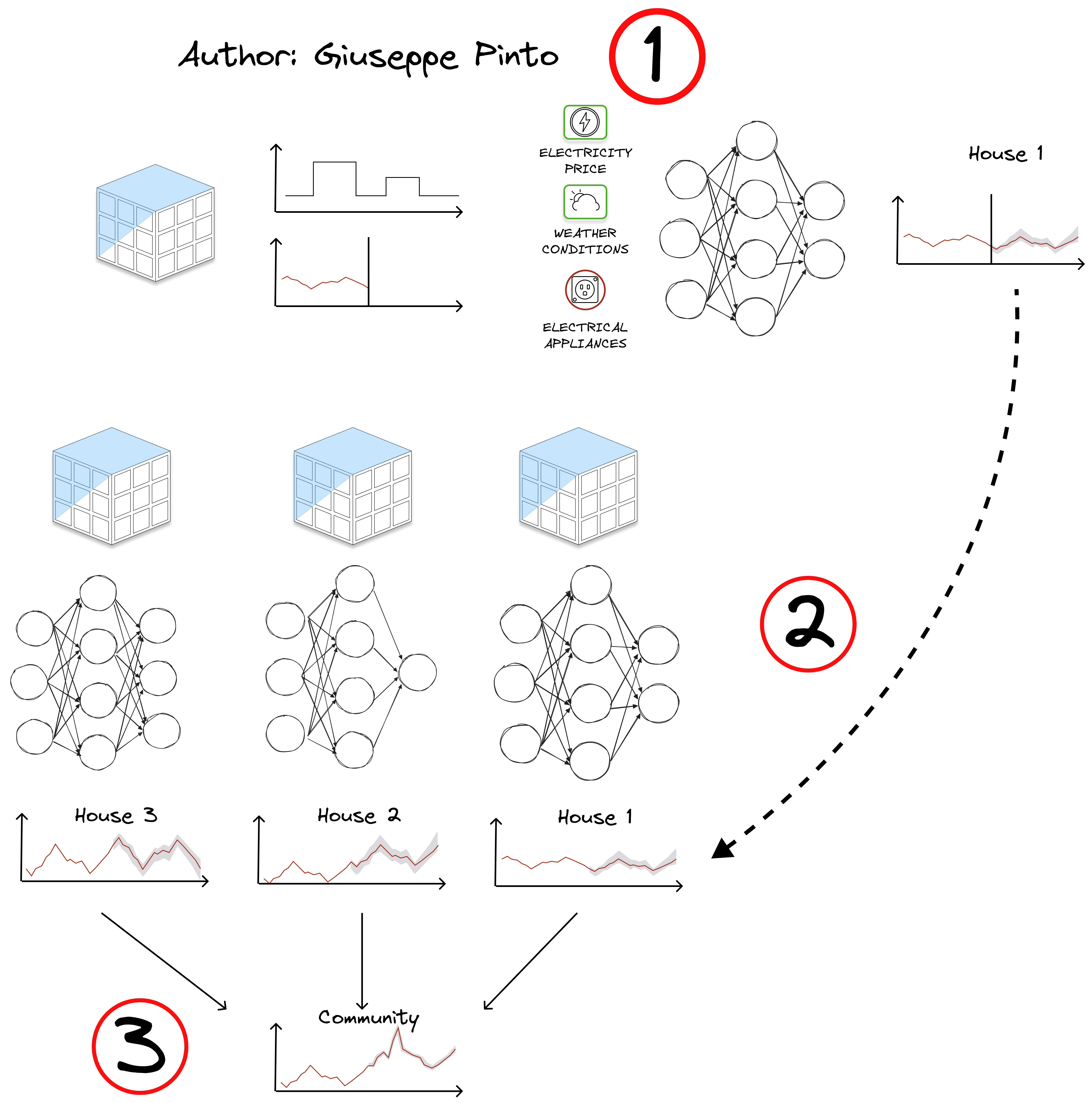
Dealing with Limited Data: If we don't have enough data or sensors for a building, we need to get creative. This could mean using data from similar buildings or making up for missing data through other methods (usually statistical methods).
Standardisation vs Customisation : Should we use the same model for every house or tailor-make one for each? Standardisation offers efficiency and consistency, while customisation allows for precision and adaptability, incorporating each house's unique features for better accuracy.
Reconciling Forecasts at Different Scales: When we're looking at energy use both house-by-house and for the whole community, we need to make sure our predictions at both levels line up. This means using techniques that can bring together and adjust forecasts at different scales.
Having gathered the necessary data, we can now define the control problem. The objective is to minimise the cost for the community and each individual house by charging and discharging the storage system. The strategy has to take into account that the cost for each house is affected by the community's overall load after the storage actions. This leads us to the last two challenges:
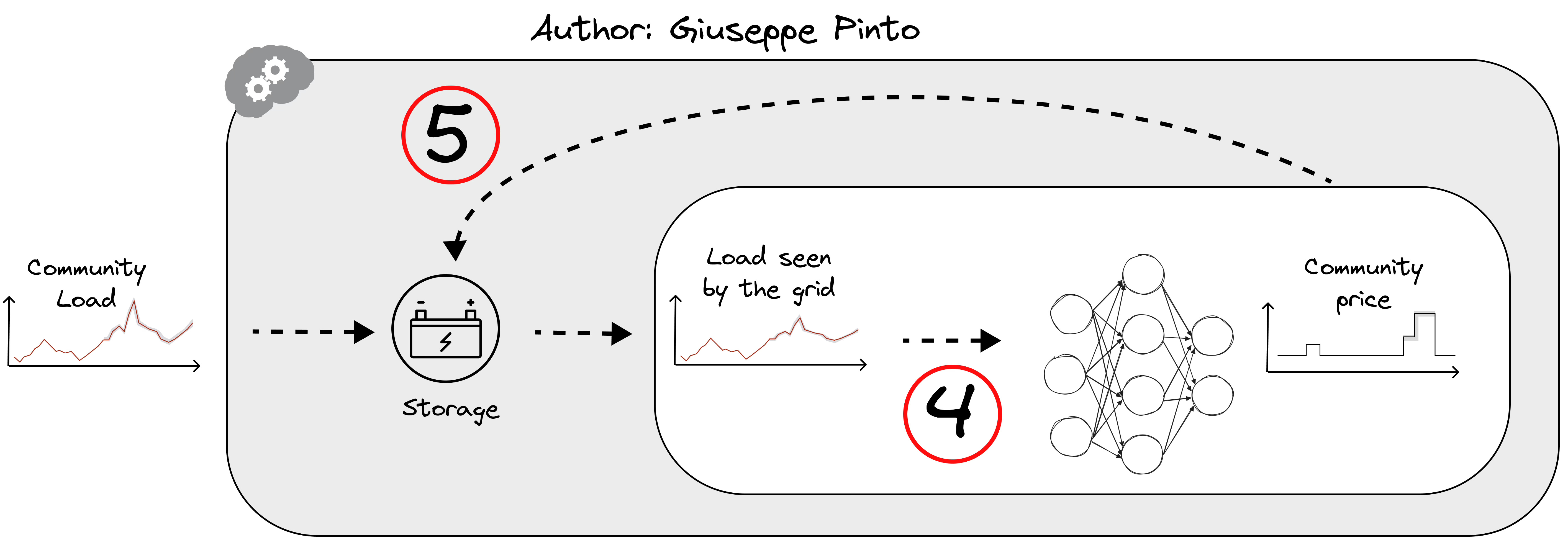
Uncertainty Propagation: With the expansion of the problem's scale, its complexity increases significantly. This demands enhanced simulation of additional information to effectively navigate and manage this growing complexity. In this case, the electricity price of the community is affected by the uncertainty of the load profile.
Complexity from Action-Dependent State Transitions: The complexity of the control problem is further amplified by the fact that the state transitions depend on the actions taken, adding another layer of complexity to the control problem.
How to deal with these problems?
While no silver bullet exist, there are a series of strategies common to a lot of machine learning applications (domain-agnostic) and few specific solutions for the building domain.
Dealing with Limited Data:
Synthetic Data Generation: Techniques like statistical imputation can fill missing data points, while synthetic data generation can create representative datasets where real data is scarce.
Transfer Learning: This involves applying knowledge gained from data-rich environments to environment with little data availability. It's particularly useful in scenarios where collecting extensive data is impractical or the time-scale is too slow. While this technique is very powerful, its applications have only been recently applied to the built environment. If you want to read more about it, I wrote an article here1.
Data Imputation with Informed Estimations: This refers to the use of simplified models, schedules or “rule-of-thumbs” in case of missing values. The most common example is occupancy schedule, that can be imputed from the type of use of the building2.
Standardisation vs. Customisation:
While standardisation and customisation are interesting points, in the context of buildings, data-scarcity is omnipresent, meaning that excluding black swan like Donate Your Data initiative3, reality is we will always have less data than needed to build prediciton models, making feature-engineering our precious ally to understand the most important features for each prediction problem.
Reconciling Forecasts at Different Scales:
Hierarchical Time Series Forecasting involves creating forecasts at various levels (individual houses and the community) and then integrating these forecasts to ensure consistency. Techniques like bottom-up or top-down approaches can be used, where forecasts are aggregated or disaggregated across levels. While it is intuitive to think about multiple buildings, it is worth noticing that even a single building might have a hierarchy (e.g., HVAC, lights, appliances).
Uncertainty Propagation:
Stochastic Modeling integrates elements of randomness into models to manage the inherent unpredictability of variables. It's particularly valuable in complex systems where a multitude of factors introduce uncertainty. A notable technique within this domain is the application of Monte Carlo methods, which use repeated random sampling to simulate and understand various outcomes in such stochastic models.
Complexity from Action-Dependent State Transitions:
Digital twins enable the testing of various scenarios and interventions, providing insights into how actions might influence building states, creating the perfect simulation environment for learning based controllers such as deep reinforcement learning (DRL) or directly a model that can be used in model predictive control (MPC) settings.
In essence, this story is about the interplay of data, scale, and prediction in AI for buildings. It's a reminder that as we deploy AI in real-world settings, we must navigate complex network of interdependencies.
This article cover a series of applications of transfer learning in smart buildings, from prediction, to modeling and control, with a specific focus on occupancy data.
As occupancy represent the most important feature for building, particular interest should be devoted in gathering data or creating models to predict occupancy levels rather than using schedules.
https://www.ecobee.com/en-us/donate-your-data/ this dataset offers a huge standardised playground for researcher to test and compare their own algorithms.
One of my favorite research topics is this one. In archetype modeling, it is very helpful.