On "The Bitter Lesson" and "Physical AI"

Recently I was thinking about a short essay by Richard Sutton, called “The Bitter Lesson”, that you can find here. This is probably one of my favorite essay, so I tried to “adapt” the main points to physical systems.
The thesis of the essay can be extracted from a couple of sentences:
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation.
These two need not run counter to each other, but in practice they tend to. Time spent on one is time not spent on the other. The human-knowledge approach tends to complicate methods in ways that make them less suited to taking advantage of general methods leveraging computation.
There were many examples of AI researchers' belated learning of this bitter lesson. One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.
The essay proceed to describe several examples, including chess, Go, speech recognition and computer vision.
Having started my career in AI as a domain expert, these sentences were particularly frustrating to hear at first, especially considering the fact I spent the past 6 years trying to merge domain expertise and artificial intelligence.
I sat down and tried to understand the rationale behind these words. And to my surprise, I realized that this is already happening in a lot of fields, but the efficiency of which algorithms are catching on domain expertise heavily depends on the specific domain we are talking about.
In particular, the points I will discuss are the following:
Sutton’s assumption is that compute is the bottleneck, but the underlying hypothesis is that computation is used in the context of either a) having a lot of data b) being able to simulate processes generating “synthetic data”.
System engineering requires a paradigm change from how to what, enabling us to go from AI to Physical AI. Or better, using domain expertise to embed knowledge without biasing the AI.
Compute is not the only bottleneck, but often counts twice
When we think about making AI better, we often focus on using faster and more powerful computers. The challenges for Physical AI are slightly different, and in my experience compute is not a “direct” bottleneck.
In several applications, from academia to industry, the main challenge was always related to either the data scarcity, or its presence clustered in specific part of the domain. To overcome this problem, the most common solution is the use of simulation environments, that increase the necessity for computational power.
Whenever you move actual things, the energy intensity is much, much higher than moving electrons between the compute units of the CPU. Moving a few electrons in the CPU in order to move fewer atoms in the real world is like a 10.000:1 trade-off kind of thing.
-Urs Holzle
Borrowing the previous quote, we can imagine how cheaper in the long run simulating processes will be. This though, will move the energy requirements from the physical world to the computational world. As a result, computational power often counts twice, being needed in the context of simulation and optimization (search and/or learn). However, right now a large amount of engineering effort is dedicated to the design of the model and the agent, making computational power a bottleneck for only a small portion of the problems.
Domain expertise as a way to set the boundaries for unnecessary complexity
The model should be good enough to allow the agent to understand how actions lead to outcomes, but any additional complexity will slow down the simulation, and can make the optimization harder. Finding the right level of detail helps to alleviate the needs for computational power, and this is valid for both simulation and optimization.
Now, if we think about a simple cooling system in a building, the system dynamics are influenced by (un)predictable factors like weather and human activities. The goal of the agent in this case might be to reduce the costs, but at the same time, we know that we do not want to cycle the equipments, even though this relationship is not immediately intuitive to non-expert.
Here, we would require an unimaginable level of detail from the model to let the agent understand that cycling the equipment is not good in the long term. Furthermore, a lot of the data necessary to understand the “health” of the equipment is not always measured, so the chances of any algorithm to achieve the optimal control actions are not bottlenecked by computational power, but are directly bonded to the models fidelity.
Alternatively, we could let the agent explore, interacting with those unsafe conditions, however, depending on the process weare simulating, the results might not be worth the risks, and this is often the case for industrial engineering.
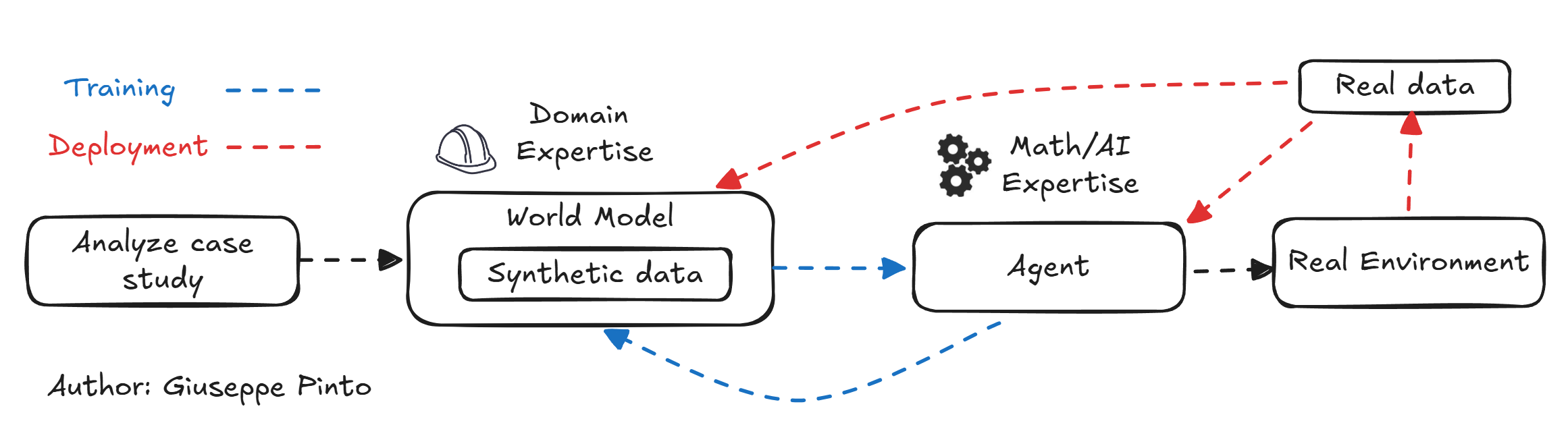
The solution here could be obtained in 3 different ways, as shown in the picture below:
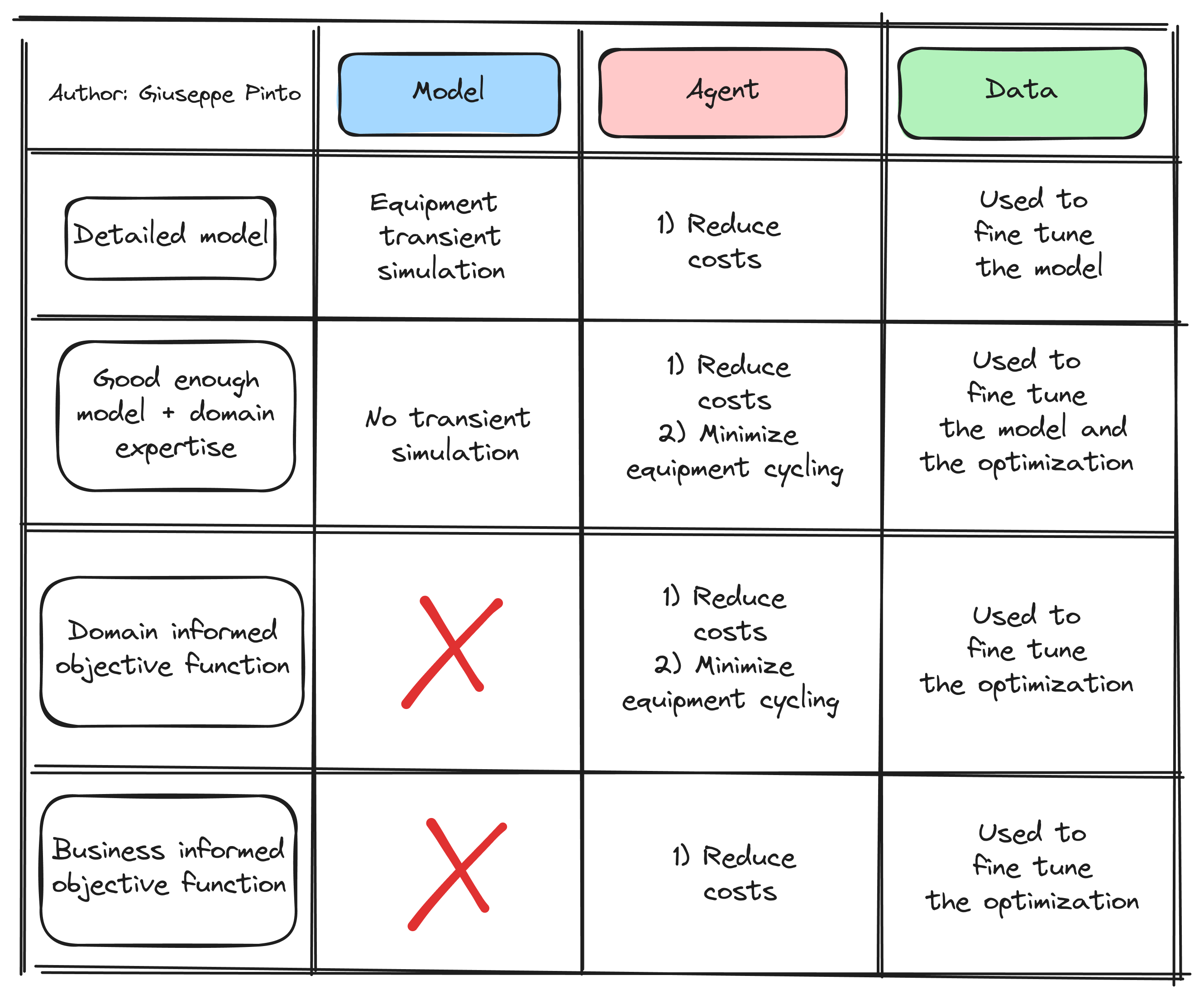
Using a very detailed model would, in principle, allow the agent to understand that cycling the equipment will lead to problems and subsequent maintenance, but the amount of interactions between the environment and the agent is very high. In this case, the real data can be used to calibrate the model.
Domain expertise can be used to “bake” some proxy into the objective functions, penalizing the agent from choosing unsafe trajectory, and let the agent find the balance between these objectives. This minimizes the complexity of the simulation environment, sacrificing the optimality of the solution. Simulation is used to generate synthetic data used to train the agent, while the real data is used to calibrate the model.
The third and fourth approaches rely only on available data to infer what the agents can do. In the realm of physical systems, the effectiveness of these solutions depend on the combination of available data and complexity of the system. The limitation is that the available data is usually limited to “good data”, not allowing the agent to understand which state "not” to explore.1 In my opinion, this is the main reason why we are seeing an explosion of data-driven supervisory control strategy.
While there is no silver bullet, and I agree with Sutton that ultimately methods that leverage computation win, physical systems have proven to play with different rules, and the necessity of a “world model” represents the true bottleneck for the large scale of physical AI applications. Among the (working) approaches described, I believe that using hybrid methods (2) is the best we can do until general methods and plug and play world models are not available.
Shifting mindset from “how” to “what”, from AI to Physical AI
I think that a as researchers/designers/engineers, a lot of pride comes from the implementation of beautiful, handcrafted solutions, chasing that 1% performance improvements with tips and tricks learned during the process, inferring what worked and what didn’t work. While this is great for personal gratification, it is poor practice for engineering projects, because it makes the solution not scalable.
In a certain sense, the vast majority of the “controllers” focuses too much on “how” to react to certain conditions, looking for that 1%, rather than describing the “what” of the problem. What are the rules of the game and what is the goal? Focusing our time on describing the “ground rule of the game” and the “goal”, allows the agent to ultimately find a better solution, being adaptive to changes.
The focus on using digital twins and ontologies aims to unlock exactly this paradigm shift. Making models of the system accurate enough that the domain expert became redundant for decision making purposes, and the combination of the embedded expertise in the model and the brute force of the algorithm are enough to solve the problems in its broad spectrum.
What will be the role of domain expertise with Physical AI?
In this scenario, the domain expert has the role of:
Finding the right level of detail to simulate and optimize
Help to identify the trade-off between the different objective functions
Let the algorithm drive, but implement guardrails to deal with system dynamics.
While the last point might sound counterintuitive, guardrails are necessary for the non-simulated level of detail, and should be used for safety reasons, rather than for optimality.
The bitter lesson of physical AI is understanding that the concept of “domain expert" able to identify what to do based on different conditions and "encode" his knowledge in the control strategy leads to suboptimal solutions, and algorithms are already better than us at this. As a result, we should move the domain expertise towards the design phase of both models and agents, reducing their costs to scale their use.