


The impact of data on designing autonomous systems
A personal journey towards designing autonomous buildings

Over the past decades, the influence of data on design and simulation has marked a significant shift from traditional physics-based models to more agile and efficient approaches.
Initially engineers used physics-based models, that despite their accuracy were costly and time-consuming. Their effectiveness is limited by the need for extensive computational resources and detailed understanding of the systems. This approach, especially in buildings, failed to scale due to the associated costs to generate and update these models.
The evolution towards reduced order models offered a middle ground, simplifying complex simulations while retaining essential characteristics of the physical systems.
Recently, the move to black-box models, has revolutionised many fields. These models, less reliant on explicit physical laws, can rapidly predict outcomes, accommodating the increasing complexity of systems and the demand for faster development cycles.
Despite the promises, end-to-end data-driven control thrived in certain applications, while still struggles to scale in others. Today, we will try to understand the opportunities and limitation of using data to model physical phenomena.
Data is the past, but can open the door for the future
Let's get this straight: sensor data is essentially a record of the past, what we've managed to gather over a specific period. But that doesn't make it any less fascinating. Data gives us a chance to update our mental model of the world and expand our knowledge. One anecdote that shows how buildings have already experimented this is related to the discovery of reinforced concrete.
A French gardener, Joseph Monier, was searching for a way to make his garden pots more durable. By embedding iron mesh into concrete, he found that his pots were not only stronger but also less likely to crack. This principle, laid the groundwork for the development of reinforced concrete, that he patented years later.
This discovery laid the foundation for a flourishing (pun intended) research on composite material, updating the way we approach building design.
Why focus on reinforced concrete? Because once we nailed down the characteristics of this new composite material through extensive testing, our problem-solving approach transformed. With the material's physics uncovered, we could lean on formulas, and nowadays software, to do the heavy lifting.
Let’s go back to our common background, and analyse the example of an equipment with a variable efficiency, function of its partial load. We could start with the product's data sheet, but soon realise that the single number (or curve) given doesn't fully capture the range of conditions the equipment faces. As an alternative, we can use what we've collected to create a new model that accurately describes the equipment's efficiency under various conditions.
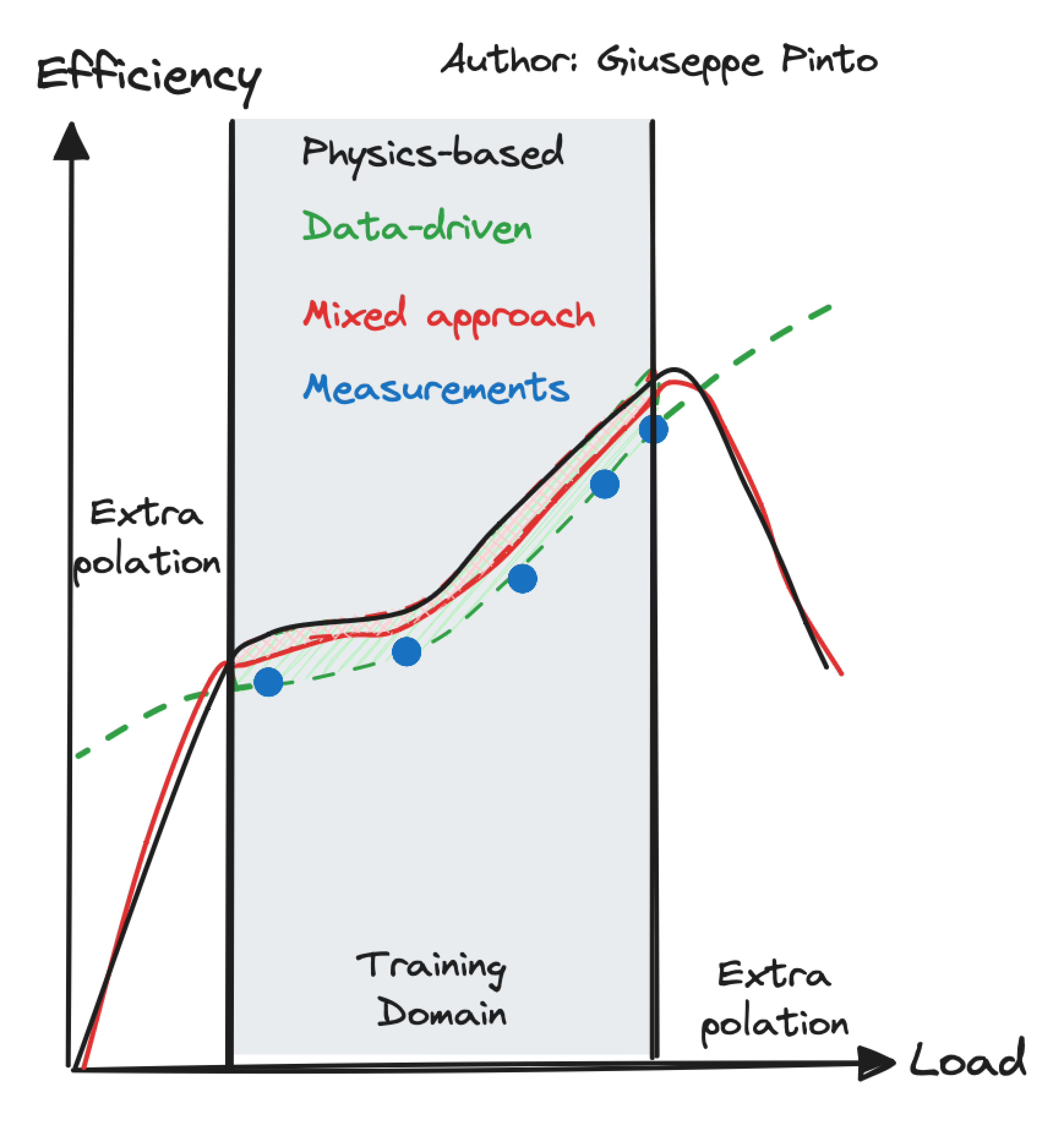
Based on the approach we decide to use, we could have a purely data-driven model (green) or a hybrid approach (red), that adapts the equations (black) we have to describe the equipment, according to the measurements (blue points).
How much data is “enough” data?
The data required greatly varies with the model's end goals. Sometimes, models are designed to shed light on the specific behaviour of equipment, or they can be integrated with controllers for state estimation. In the latter, we will see a “propagation” between the prediction of the model (a state) and the action of the controller.
Now, bear with me, because we will try to understand how this concept applies to building thermal dynamic.
The evolution of the building thermal dynamic is a complex interaction of several key actors, including solar gains, heat losses and internal loads (like the heat from appliances and the presence of people). Meanwhile, the goal of the HVAC is to balance these effects, injecting or extracting heat as needed to maintain the desired indoor climate.
This lead us to an inherently high-dimensional space, and as a result, we suffer from the “curse of dimensionality”. Also, the data we have usually cover very specific conditions, swinging around constant set points. This is inherently bad to learn a generalised model, focusing all the available data points in a limited part of the domain.
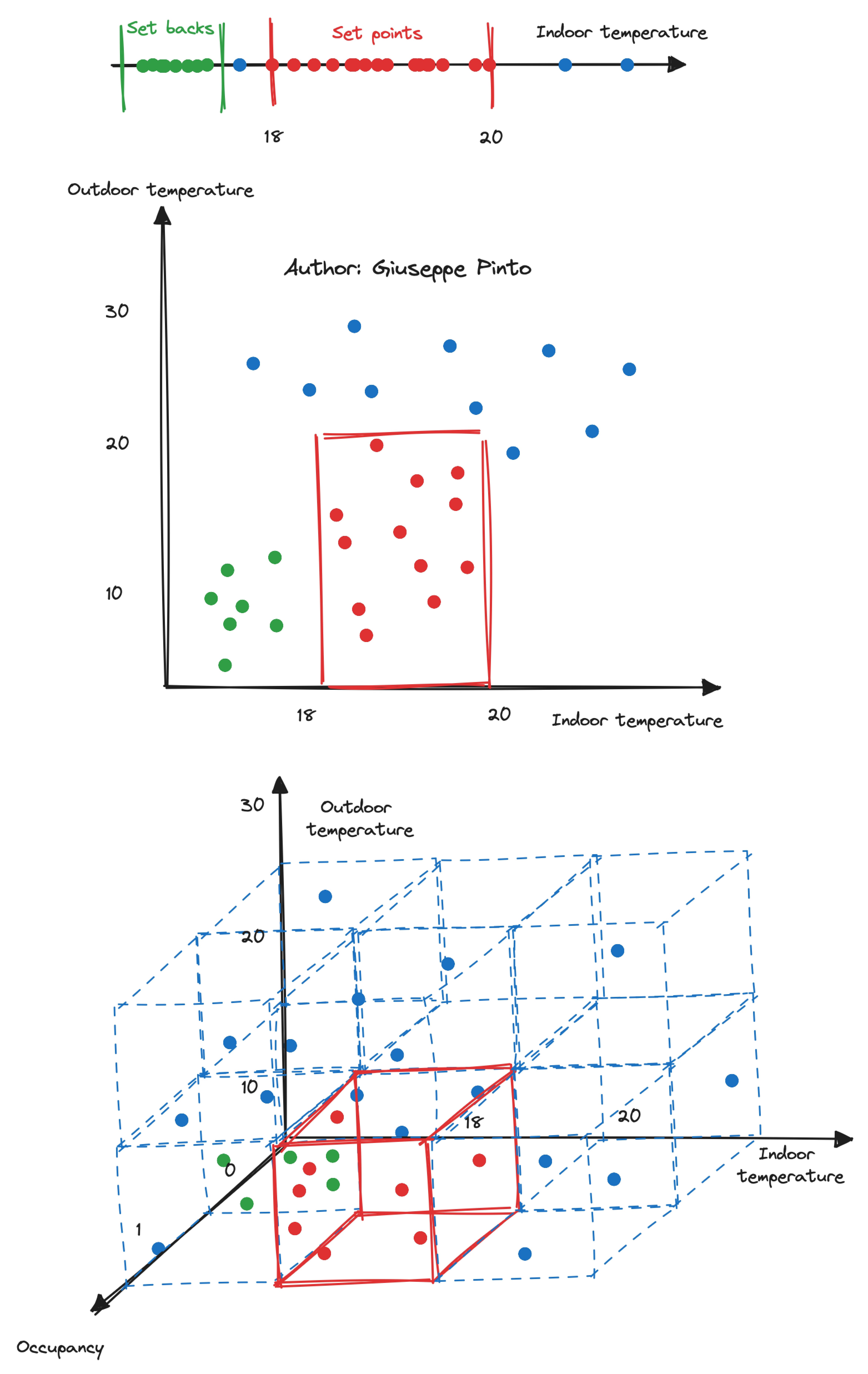
As an example here I am showing how a common sensor might distribute the data over a 3D domain space, being highly unbalanced and “sparse”. Once you also add humidity, CO2 concentration, the amount of heat injected by the HVAC systems, it becomes n-dimensional and even sparser.
It is important to understand that machine learning models are trained using the available data (the past), and, once deployed, they use real-time data (the present/near-past) to predict what it is going to happen (the future).
This only holds given the present have a similar data distribution of the past. If we forget this assumption, we might be tempted to use the model to extrapolate in unseen scenarios, as previously shown.
One basic example is trying to use a machine learning model to predict the thermal response of a building in a demand response setting, when you have to suddenly limit your HVAC consumption.
This example shows a combination of data that we do not often see, a high-external temperature, combined with low/absent cooling (to comply with the demand response event). This usually lead to discomfort, and as a result, we do not have a lot of data for this kind of scenarios, putting us in a dangerous situation.
The risk of using a pure machine learning approach here is that if the model didn’t learn the proper relationship between external temperature, energy injected and occupancy/loads, it will predict something very different from the reality.
Now, imagine that this is just half of the problem, and using a full data-driven approach involves a predict-optimise approach. When combining the two, the data requirements can skyrocket, based on the kind of predictions and decisions involved.
This graph summarises some of the lessons learned over the past 5 years dealing with data-driven control, designing agents and modelling systems in buildings.
When dealing with energy system optimisation, the amount of “flexibility” that the building has influences the complexity of the control. Also, if your goal is to optimise the production (charing or discharging storage/batteries) without modifying the demand, the job is fairly easy, and the data can directly point you to a good solution fairly fast. A purely data-driven approach (let’s talk about “deep reinforcement learning”, requires around 5 epochs, or 5 years worth of data)1.
However, if your goal is more complex, and you would like to understand how much energy inject into the system to minimise the discomfort while minimising the objective costs, you will have to learn the dynamic of the system. Then the data requirement explodes from 5 to 50 years of data, a tenfold increase2.
Understanding building dynamics is necessary to exploit thermal mass, enabling optimal start and stop, demand response and a better comfort. However, as you might have noticed, the data requirement is just prohibitive for this kind of applications. Even 5 years of quality data are very hard to obtain, so… what’s the solution?
Generate data (at your own risk), or embed the physics into your model!
In the next article, we are going to discuss how re-insert back the physics into the equation, finding the right balance between the two when designing autonomous systems.
Assuming you have a perfect oracle to predict the demand